Standardize AI Context with Open Knowledge Format (OKF)

Writer

Semantic Unbaking: Why Open Knowledge Format Matters for Governed AI Context
Most organizations are not short on knowledge. They are drowning in it.
The real problem is that the knowledge an AI agent needs is scattered across wikis, metadata catalogs, shared drives, notebooks, runbooks, code comments, and the brains of a few over-subscribed experts. Every new agent, assistant, chatbot, or automation workflow has to reassemble that context again. That is not just an engineering problem. It is a governance problem, a cost problem, and eventually a business-value problem.
This is where Google’s Open Knowledge Format (OKF) becomes interesting.
Google Cloud introduced OKF as an open, vendor-neutral, human- and agent-friendly specification for representing organizational knowledge as plain Markdown files with YAML frontmatter. The official v0.1 draft describes OKF as intentionally minimal: no schema registry, no central authority, no required runtime, and no mandatory SDK. If you can open a Markdown file and read YAML, you can inspect it. If an agent can traverse files and links, it can consume it. 1 2
That simplicity is the point.
For IT leaders, FinOps practitioners, and tenant administrators, OKF is less about “cool agent memory” and more about a strategic control plane for context. It gives you a way to decide what knowledge is trusted, how it is packaged, who can change it, how it is versioned, and how much context an AI system should consume before it starts burning budget.
The Mental Model: Stop Serving Raw Ingredients to Every Agent
Think of your enterprise knowledge as food production.
Traditional RAG is like asking every chef to walk through the warehouse, inspect raw ingredients, read every supplier label, infer the recipe, and cook the meal from scratch every time someone orders lunch.
A large context window is like making the warehouse bigger. Useful, but expensive if every meal requires dragging half the warehouse into the kitchen.
OKF is different. It is the prepared recipe book.

Raw documents still matter. But the agent does the expensive synthesis once: extract the concepts, define the joins, capture the rules, link the dependencies, note the contradictions, and store the result as durable Markdown knowledge. After that, downstream agents can read the prepared, governed knowledge instead of re-processing the same raw material on every request.
Key takeaway: OKF does not replace your systems of record. It creates a portable, inspectable knowledge layer above them.
Why Leaders Should Care: Context Is Now a Cost Center
For a developer, AI context feels like prompt engineering. For a FinOps team, it is metered consumption.
Most modern foundation-model pricing is token-based. That means every repeated policy document, schema dump, meeting transcript, runbook, and knowledge-base export you pass into a model has a financial footprint. Google Gemini API pricing, for example, is published per million input and output tokens, with separate pricing by model tier and features such as context caching, batch processing, and grounding. Google also notes that paid Gemini API usage receives higher rate limits, access to advanced capabilities, and different data-use terms than free usage. 3 4
The audience for OKF should include the people who own:
- AI platform cost management
- Tenant-level rollout controls
- Knowledge governance
- Data-retention and review workflows
- Model-routing and agent-routing decisions
- Business-value measurement
If AI agents become a shared enterprise service, context cannot remain an unmanaged free-for-all.
Directional Cost Intuition: The Token Waste Problem
The numbers below are directional planning aids, not vendor quotes. Always validate pricing against your model provider’s current rate card before budgeting.
Imagine a support agent that answers internal policy questions.
| Scenario | What happens | Directional cost intuition |
|---|---|---|
| Raw-document prompting | Every request includes large HR, IT, and security documents | High repeated input-token spend and slower responses |
| Traditional RAG | The system retrieves chunks from raw documents at query time | Better than full dumps, but still repeatedly re-synthesizes meaning |
| OKF-style compiled knowledge | Policies are distilled into governed concept pages and playbooks | Lower repeated context, clearer provenance, easier review |
A simple planning model:
- Suppose a raw prompt pulls 80,000 input tokens of policy and documentation per request.
- Suppose an OKF concept/playbook route pulls 8,000 input tokens instead.
- At 10,000 requests per month, that is a reduction from 800 million input tokens to 80 million input tokens.
- If your chosen model input price is in the broad range of $0.25 to $2.00 per million input tokens, the input-token line item moves from roughly $200 to $1,600 down to roughly $20 to $160.
Again, this is not a quote. It is a mental calculator. The point is that context design can change your cost curve by an order of magnitude before you even start negotiating discounts or optimizing infrastructure.
Rule of thumb: If the same context is being sent repeatedly, it probably wants to become governed knowledge, not prompt baggage.
OKF in One Sentence
OKF is a portable knowledge bundle: a directory of Markdown files, each with YAML metadata, linked together so humans and agents can read the same governed knowledge graph.
Google’s official materials describe OKF as “just markdown,” “just files,” and “just YAML frontmatter.” The spec defines a knowledge bundle as a hierarchical collection of knowledge documents, a concept as a single unit of knowledge represented by one Markdown document, and a concept ID as the file path without the .md suffix. 1 2
That makes it boring in exactly the right way.
Boring formats win in enterprises because they are:
- readable in plain text
- reviewable in pull requests
- diffable in Git
- portable between tools
- easy to back up
- friendly to records-management workflows
- inspectable by security and compliance teams
From RAG to Compiled Knowledge
Andrej Karpathy’s LLM Wiki pattern popularized a useful shift: instead of retrieving fragments from raw documents on every query, an LLM can incrementally build and maintain a persistent, structured wiki. When new material arrives, the agent reads it, extracts important concepts, updates existing pages, links related ideas, and flags contradictions. Karpathy’s gist describes the wiki as a persistent, compounding artifact rather than stateless retrieval from scratch. 5
OKF formalizes that pattern into a common format.
| Dimension | Traditional RAG | Large context prompting | OKF-style compiled knowledge |
|---|---|---|---|
| Primary behavior | Retrieve chunks at query time | Stuff more source material into the prompt | Maintain curated concept files over time |
| Cost profile | Repeated retrieval and synthesis | High input-token spend | Lower repeated context if curated well |
| Governance model | Often hidden in retriever settings | Hard to review prompt payloads at scale | Review Markdown and metadata in version control |
| Interoperability | Depends on vector store, chunking, and app logic | Depends on model and prompt design | Plain files and links, portable across tools |
| Best fit | Broad search over large corpora | One-off deep analysis | Durable business rules, playbooks, metrics, schemas |
The strategic shift is important: RAG answers questions. OKF helps package trusted institutional knowledge so many agents can consume it consistently.
The Architecture: A Knowledge Bundle You Can Govern
A practical OKF bundle can look like this:
The exact folder taxonomy is not the standard. The important pattern is that each knowledge unit is addressable, linked, and described by frontmatter.
A simplified concept file might look like this:
The official OKF spec treats type as the only required frontmatter field, while fields such as title, description, resource, tags, and timestamp metadata are part of the small structured set that makes knowledge queryable and traversable. 2
Governance translation: This is not just metadata. It is the administrative handle that lets you route, review, expire, refresh, and authorize knowledge.
The Traditional LLM Wiki Anatomy
Before OKF, many teams were already building what Karpathy called an LLM Wiki: a Markdown-first knowledge base that an agent maintains over time. The pattern has four basic moving parts:
| Component | What it does | Why it matters |
|---|---|---|
index.md | Acts as the top-level map of available knowledge | Gives the agent a cheap first read before it spends tokens opening detailed files |
| Entity and concept documents | Capture one concept, entity, system, metric, or policy per file | Prevents giant pages from becoming another long-context dumping ground |
| Progressive disclosure files | Break large topics into smaller linked pages | Lets the agent open only the next relevant layer of knowledge |
| Related concept links | Connect files through relative Markdown links and shared tags | Turns a folder of notes into a navigable local knowledge graph |
This is the reason OKF matters. It does not invent the second-brain pattern. It standardizes the contract so one team’s agent does not need to guess another team’s folder structure, metadata names, or linking conventions.
YAML Frontmatter: The Small Contract That Keeps Agents Sane
The source material emphasized an important point: the YAML frontmatter is not cosmetic. It is the agent’s first routing decision.
In OKF, type is the anchor field. The source examples also used optional or recommended fields such as title, description, resource, tags, timestamp metadata, and relationship fields such as related_videos for media-heavy bundles.
For governance teams, the tiny frontmatter block becomes a control surface:
typehelps you separate policies, playbooks, references, systems, and entities.titleanddescriptionhelp agents decide whether a file is worth opening.tagscreate cross-cutting relationships that graph visualizers can use to show clusters and dependencies.resourcelinks the curated concept back to an authority.timestampor timestamp-like metadata supports freshness reviews.related_videosor similar relationship fields are useful when a bundle includes video tutorials, training assets, or media-based knowledge.
Rule of thumb: If the metadata is inconsistent, your agents spend budget discovering structure instead of solving the user’s problem.
The Producer/Consumer Contract
OKF is also a Producer/Consumer contract. The producer might be a human, a data pipeline, a documentation export, or an agent that creates the bundle. The consumer might be a different local agent, a governance workflow, a graph viewer, or an enterprise assistant. The value of the standard is that the producer and consumer do not need to share the same proprietary SDK, database, taxonomy, or runtime. They only need to agree on the small OKF surface: files, frontmatter, indexes, links, and readable Markdown.
Building and Migrating with SPEC.md
One tactical trick from the source material is worth preserving: use the OKF specification itself as an implementation prompt.
Because OKF is intentionally small, you can pass the official SPEC.md to a coding agent and ask it to:
- generate a new bundle from raw material;
- refactor an existing Markdown wiki into OKF conventions;
- split “one giant page” into “one concept per file”;
- add YAML frontmatter consistently;
- create or refresh
index.mdfiles; - propose cross-links between related concepts;
- produce a migration report for human review.
For large migrations, the source material described using sub-agents to traverse different historical sections in parallel. That is a sensible pattern, but it needs guardrails: partition the source corpus, require deterministic output paths, force each sub-agent to produce a change plan, and merge only after human review.
A safe enterprise migration workflow looks like this:
Two-Tier Bundle Architecture and CLI Navigation
The source examples included an AI coding knowledge bundle with two levels of indexing. This pattern is useful for enterprises because it lets you scale without giving every agent a sprawling, flat directory.
| Layer | Purpose | Example |
|---|---|---|
| Top-level index | Lists all bundles the agent can access | finance-cost-rules, ai-coding-mental-models, incident-response |
| Bundle-level index | Lists sections inside one bundle | concepts/, videos/, playbooks/, references/ |
| Concept ID | Stable address for a specific knowledge file | concepts/piv-loop, concepts/context-engineering |
For example, an AI coding bundle might expose concepts such as the PIV Loop, meaning Plan, Implement, Validate, and Context Engineering as separate concept files. A lightweight CLI can then help agents list bundles, view indexes, and read exact concept IDs instead of scanning the entire repository.
Conceptually, the commands might look like this:
This is not an OKF requirement. It is a practical operations pattern. The standard gives you files and metadata; your CLI gives agents a disciplined way to navigate them.
Practical Playbooks Worth Encoding
The source material included two playbook examples that are good candidates for OKF because they are repeatable, judgment-heavy workflows.
Communication Voice Playbook
Agents often drift into generic corporate language. A communication_voice.md playbook can encode style rules such as:
- use first-person singular, such as “I”, when the output represents an individual consultant;
- avoid generic corporate filler;
- keep the tone authoritative, direct, and accessible;
- preserve the author’s opinionated voice;
- rewrite dry phrasing into language a real stakeholder would read.
For IT and adoption leaders, this matters because consistent communication is part of governance. If AI-generated stakeholder updates sound generic or misrepresent the speaker, trust erodes quickly.
Rapid Algorithm Impact Diagnostics
The source material also described a playbook for diagnosing the impact of a major search or ranking algorithm change. In an OKF model, the diagnostic playbook can tell the agent:
- which historical traffic metrics to inspect;
- which dashboards or sources are authoritative;
- which affected pages, campaigns, or segments to compare;
- which known caveats to include;
- which final report structure to produce.
The broader lesson applies beyond SEO. Any recurring incident, cost anomaly, tenant configuration drift, or adoption-metric drop can become an OKF playbook.
Local-First Architecture, Backups, and Tooling
The source articles also described a local-first implementation model. The core idea is simple: keep the OKF bundle as files, not as something trapped in a proprietary application.
Practical hosting options include:
- a Git repository for review, versioning, rollback, and audit;
- Obsidian for browsing Markdown and graph-style relationships;
- Notion or other knowledge tools as authoring or viewing layers, where appropriate;
- local folders for fast agent access in developer workstations;
- NotebookLM, Gemini, Claude-style coding agents, Antigravity-style local orchestration, or custom local agents to draft, refactor, and query content.
The source material mentioned Gemini 3 Flash Preview as a high-throughput model option for recurring Markdown ingestion and transformation. Because model names and availability change quickly, treat that as an example of a fast, lower-cost model tier, not as a permanent architectural dependency.
Backup strategy is non-negotiable:
- store bundles in a dedicated workspace;
- commit changes to Git;
- schedule automated daily differential backups;
- require pull requests for production bundles;
- test rollback before you let agents mutate files;
- keep
log.mdor equivalent change records for agent-authored updates.
Production Observability: Watch the Agent, Not Just the App
When agents traverse knowledge dynamically, you need observability at the agent-run level, not only application logs.
The source material specifically mentioned PostHog integration within an open-source harness called Archon as an example pattern for tracking agent runs, parameter usage, and user interactions. I have kept this as an implementation example rather than an OKF claim because it is not part of the OKF specification itself.
The operational telemetry you want includes:
- which bundle and concept IDs were read;
- how many input and output tokens were consumed;
- which model tier was selected;
- whether a tool or CLI navigation command was used;
- whether the response cited approved sources;
- whether the user accepted, corrected, or escalated the answer;
- whether a mutation plan was proposed, approved, or rejected.
This is where FinOps, governance, and platform engineering meet. Without observability, you cannot prove whether OKF improved quality, reduced spend, or increased risk.
skills.md vs OKF: Similar Shape, Different Contract
The source material called out a useful distinction between community skill files and OKF bundles.
A skills.md-style file often teaches an agent how to behave in a specific repo, project, or workflow. It is usually local, procedural, and tailored to one agent environment.
OKF is broader. It packages knowledge as portable concepts, playbooks, references, and systems so different agents can consume the same knowledge without the original author being present.
| Pattern | Best used for | Governance concern |
|---|---|---|
skills.md or agent instruction files | Local behavior, coding conventions, repo-specific workflow guidance | Can become agent-specific and hard to reuse |
| OKF bundle | Portable organizational knowledge, playbooks, schemas, metrics, and domain rules | Needs ownership, freshness, access boundaries, and review |
They overlap structurally because both are Markdown-friendly. They differ in ambition: skills.md instructs an agent; OKF packages knowledge for many agents.
From SEO to Agentic Accessibility
The source material introduced the phrase Agentic Accessibility: the idea that websites and organizations will increasingly expose knowledge in forms that agents can discover and consume directly.
One proposed discovery mechanism is llms.txt, a root-level file that points agents toward high-value machine-readable or agent-readable resources, potentially including public OKF bundles. This should be treated as an emerging design direction, not a universal standard of enterprise governance yet.
The practical direction is clear, though: if agents become major consumers of organizational knowledge, then publishing clean, approved, machine-traversable context becomes a new part of digital operations.
Dynamic Community Ingestion and Personalized Delivery
The source material also described a future pattern where community discussions, edge-case discoveries, and industry updates are ingested into OKF pipelines. For example, a community platform API such as Mighty Networks could provide discussion transcripts that an agent turns into references, concepts, and newsletter briefs.
A careful implementation would look like this:
- ingest community discussions or transcripts;
- classify topics and sensitivity;
- draft reference nodes and concept updates;
- require human review for claims and recommendations;
- publish approved updates into the OKF bundle;
- generate hyper-personalized newsletters for specific stakeholder groups.
The value is not automatic content generation. The value is turning noisy community learning into curated, governed organizational memory.
The Minimalism Critique
Some critics argue OKF is too simple for enterprise knowledge. That critique is fair if you expect OKF to replace a data catalog, policy engine, ontology system, records platform, or enterprise search stack.
But that is not the job of OKF.
The better mental model is this: OKF is the interoperability surface, not the whole control plane. It standardizes the few conventions required for producers and consumers to exchange knowledge without agreeing on a proprietary platform.
Minimalism is what makes adoption plausible:
- people can author it by hand;
- agents can generate it;
- Git can diff it;
- security teams can inspect it;
- local tools can browse it;
- future platforms can ingest it.
The Governance Levers That Matter
If you are a tenant administrator or platform owner, OKF should trigger a familiar question: Where are the controls?
Here are the strategic levers.
| Control lever | Why it matters | Practical implementation |
|---|---|---|
| Ownership | Every knowledge area needs an accountable owner | Add owners in repository rules, CODEOWNERS, or adjacent governance docs |
| Versioning | Agent knowledge should be reversible | Store bundles in Git and require pull requests for production bundles |
| Review gates | Prevent agents from silently rewriting business policy | Use human review for high-impact concept and playbook changes |
| Scope | Keep agents from reading everything by default | Route agents to specific bundles by business domain or sensitivity |
| Freshness | Outdated knowledge is operational risk | Add review dates, stale-content reports, and periodic bundle audits |
| Cost routing | Not every query deserves the most expensive model or biggest context | Use lightweight models for classification and bundle selection, higher-tier models for final reasoning |
| Auditability | Administrators need to explain what an agent relied on | Require responses to cite concept IDs and source links where appropriate |
The governance win is not that OKF magically enforces policy. It is that OKF makes policy visible in a format your existing controls can understand.
Safe Rollout Playbook for Enterprises
Do not start by converting your entire wiki. That is how knowledge-management programs go to die.
Start with one expensive, repeatable, high-value workflow.
Phase 1: Pick the first domain
Choose a domain where context errors are costly and repeated questions are common.
Good first candidates:
- cloud cost allocation rules
- software purchasing and license governance
- incident response runbooks
- executive metric definitions
- data-access request procedures
- customer support escalation paths
Avoid starting with:
- highly sensitive legal advice
- unclear ownership areas
- content with no authoritative source
- fast-changing information that lacks a review owner
Phase 2: Build a thin knowledge bundle
Create only what you need:
index.mdfor navigation- five to ten core concepts
- two to three playbooks
- links to authoritative source systems
- a short
log.mdthat records major changes
Treat the first bundle as an operating model, not a migration project.
Phase 3: Add review gates
Before agents can use the bundle in production:
- assign owners for each domain
- require review for changes to
concepts/andplaybooks/ - mark unverified material clearly
- capture source links in
resourceor the body - block direct mutation of production bundles by autonomous agents unless reviewed
Phase 4: Route agents deliberately
The worst architecture is one where every agent sees every bundle.
Use a routing layer:
| Query type | Recommended route |
|---|---|
| Simple lookup | Search index or low-cost model over selected concept files |
| Business-rule explanation | OKF concept plus source citation |
| Procedure execution | OKF playbook plus human approval where needed |
| Complex multi-domain analysis | Bundle selection first, then controlled context expansion |
| High-risk decision | Human-in-the-loop review and logged evidence trail |
Phase 5: Measure business value
Do not measure OKF success by file count. Measure it by operational impact.
Useful KPIs:
- reduction in average input tokens per request
- reduction in duplicate agent prompts and repeated document ingestion
- percentage of answers with traceable concept IDs
- number of stale concepts detected and refreshed
- response latency improvement
- deflection of repeated internal questions
- reduction in manual handoffs to subject-matter experts
Admin Mental Model: OKF as a Context Budget
Tenant administrators already understand quotas, conditional access, retention labels, and permission boundaries. OKF is similar, but for AI context.
You are not just asking, “Can this user access the data?”
You are also asking:
- Should this agent read the raw source or a curated concept?
- Should this workflow use a low-cost model, a high-reasoning model, or a cascade?
- Should the answer cite an approved knowledge file?
- Is the bundle fresh enough for this decision?
- Is the workflow allowed to mutate knowledge, or only read it?
- Does this knowledge belong in a shared bundle or a restricted domain bundle?
That is the difference between AI experimentation and AI operations.
Platform Routing Strategy: The FinOps Layer Nobody Talks About
Model selection matters, but context selection often matters more.
A simple enterprise routing pattern:
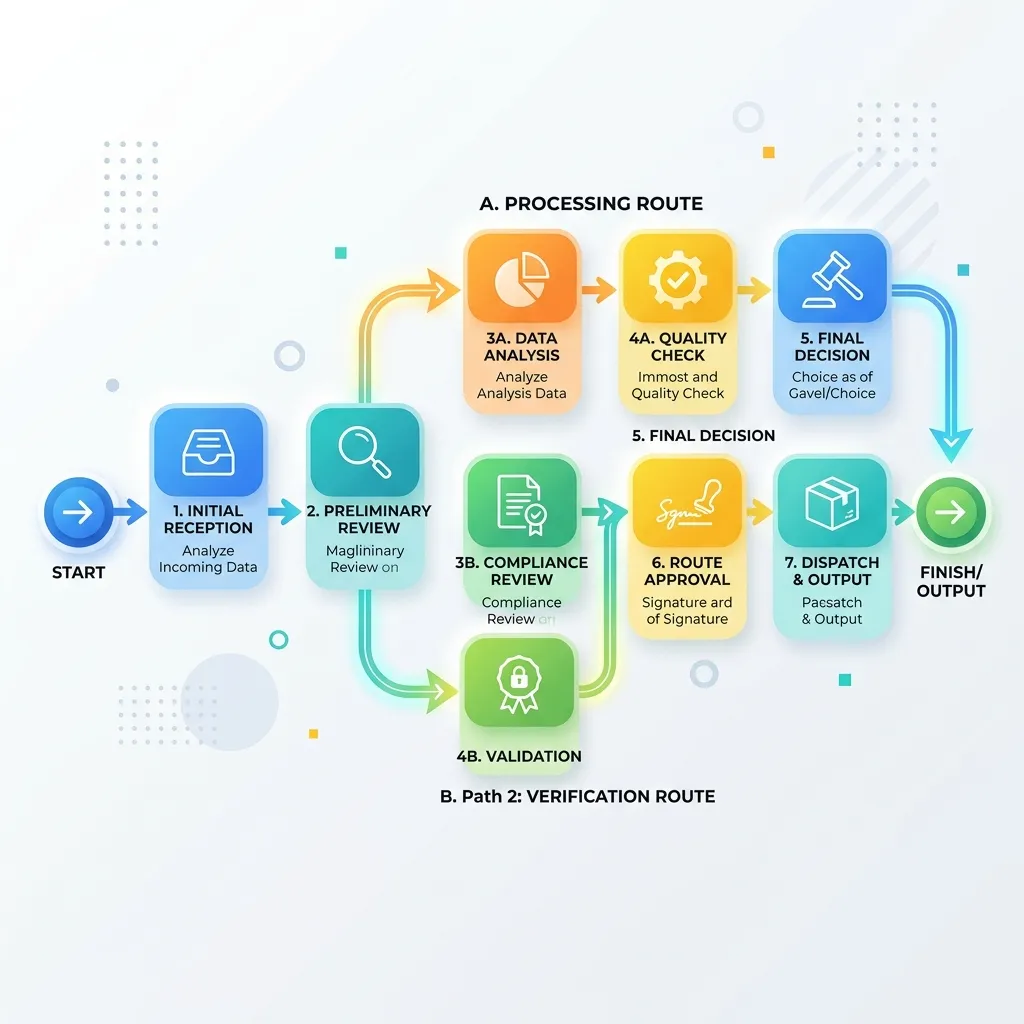
The financial logic is straightforward:
- use cheaper, faster models for classification, routing, extraction, and simple lookup
- reserve stronger models for synthesis, ambiguity, high-value reasoning, and executive-facing output
- avoid sending raw long-form documents when a curated concept page is enough
- cache stable context where your model provider supports it
- measure token usage by workflow, not only by application
Google’s public pricing pages show that token charges vary substantially by model tier and feature, and that batch and context-caching options can materially affect cost for supported workloads. 3 6
Rule of thumb: Model routing saves money in percentages. Context routing can save money in multiples.
Practical Use Cases for IT, FinOps, and Tenant Admins
1. Cloud Cost Allocation Rules
Most cloud-cost confusion is not caused by missing data. It is caused by inconsistent interpretation.
An OKF bundle can define:
- what counts as shared platform cost
- how chargeback and showback work
- which tags are mandatory
- how reserved capacity is allocated
- who approves exceptions
- which dashboards are authoritative
Now your FinOps assistant can answer with the same rules every time, instead of improvising from spreadsheets, slides, and tribal knowledge.
2. AI Agent Rollout Governance
Before an agent goes live, it needs operating rules:
- approved data sources
- escalation paths
- restricted actions
- answer-citation requirements
- user groups allowed to use it
- cost thresholds and kill switches
- review cadence
These are excellent OKF playbooks because they are procedural, repeated, and governance-heavy.
3. Metrics and Executive Reporting
Every company has a metric-definition problem.
“Active customer,” “qualified pipeline,” “cloud consumption,” “case deflection,” and “AI adoption” often mean different things in different meetings.
OKF can make metric definitions durable:
- metric name
- business definition
- calculation logic
- source system
- known caveats
- owner
- related dashboards
This is where OKF becomes executive hygiene. If the metric matters, the definition should not live only in a slide deck.
4. Data and Schema Guidance
Google’s OKF materials specifically discuss the problem of fragmented organizational context such as schemas, metric meanings, runbooks, join paths, and deprecation notices. 1
That maps cleanly to data-platform governance. Instead of asking every analytics agent to infer how tables join, store the approved joins, caveats, and business definitions as concepts.
Human-in-the-Loop Orchestration: Let Agents Draft, Not Dictate
An OKF knowledge base should not mutate randomly. If production agents can rewrite business knowledge with no review, you have built a very fast documentation-corruption machine.
A safer ingestion workflow:
- Source intake: A human or system submits a source document, URL, transcript, or schema export.
- Draft analysis: The agent proposes concepts, updates, links, and contradictions.
- Change blueprint: The agent explains which files it would create or modify.
- Human review: A domain owner approves, edits, or rejects the changes.
- Versioned commit: The approved update lands in Git or an equivalent versioned store.
- Production sync: Approved bundles are published to the agent runtime.
- Monitoring: Usage, citations, stale files, and user feedback are tracked.
Quick example: If a new cloud cost-allocation policy is published, the ingestion agent should not silently overwrite the production FinOps playbook. It should propose updates to the policy concept, downstream chargeback playbooks, and any affected executive-reporting definitions.
OKF vs MCP: Different Layers, Different Jobs
Do not confuse OKF with the Model Context Protocol (MCP).
Anthropic introduced MCP in November 2024 as an open standard for connecting AI assistants to external systems, data sources, tools, and development environments. Anthropic later donated MCP to the Agentic AI Foundation under the Linux Foundation in December 2025. 7 8
OKF and MCP are complementary.
| Layer | MCP | OKF |
|---|---|---|
| Core job | Connect agents to tools and live systems | Package curated knowledge for humans and agents |
| Mental model | USB-C port for tools | Recipe book for trusted context |
| Runtime dependency | Protocol and server/client architecture | Plain files and Markdown links |
| Best fit | Querying systems, invoking actions, retrieving live data | Governing definitions, playbooks, schemas, and institutional knowledge |
| Admin concern | Tool permissions, authentication, audit, action safety | Knowledge ownership, freshness, provenance, cost, review workflow |
A practical enterprise architecture will likely use both: MCP for live capabilities and OKF for the durable knowledge that explains how, when, and why those capabilities should be used.
What to Avoid
OKF is promising, but it is not magic.
Avoid these traps:
| Trap | Why it hurts | Better approach |
|---|---|---|
| Converting everything | Creates a new unmanaged wiki | Start with one high-value workflow |
| Treating generated pages as truth | Agents can summarize incorrectly | Require source links and owner review |
| No freshness model | Old playbooks become silent risk | Add review cadence and stale-content checks |
| Giant concept files | Recreates long-context waste | Keep concepts focused and link related pages |
| No cost telemetry | You cannot optimize what you cannot see | Track token usage by workflow and bundle |
| No access strategy | Sensitive context leaks across use cases | Scope bundles by domain, sensitivity, and role |
Decision Guide: When Should You Use OKF?
| If you need to… | OKF fit? | Why |
|---|---|---|
| Standardize metric definitions across teams | High | Concepts and links work well for durable definitions |
| Govern AI assistant answers for internal policy | High | Playbooks and reviewed concepts reduce improvisation |
| Replace every enterprise content system | Low | OKF is a format, not a full content-management platform |
| Store live transactional data | Low | Keep systems of record where they are |
| Package reusable domain knowledge for agents | High | This is the core use case |
| Execute actions against business systems | Medium | Pair OKF with MCP or platform APIs |
| Reduce repeated prompt context | High | Curated concepts can reduce repeated input-token spend |
Getting Started This Week
If you want a pragmatic first move, do this:
- Pick one workflow where repeated context is expensive or risky.
- Create a small OKF bundle with an
index.md, a few concepts, and one playbook. - Store it in Git.
- Require human review for changes.
- Route one low-risk assistant to use only that bundle.
- Log which concept files were used and how many tokens were consumed.
- Compare answer quality, latency, and token usage against your current approach.
Do not sell this internally as a new documentation project. Sell it as AI context governance.
The Bigger Picture: Agentic Accessibility
The web was built for humans first, then search engines, then APIs. AI agents are forcing another shift: knowledge now needs to be legible to machines without becoming illegible to people.
OKF is one early step in that direction. It does not solve every problem. It does not replace data catalogs, RAG systems, MCP servers, knowledge graphs, security controls, or human judgment. But it gives enterprises a simple, portable way to package the knowledge agents need most often.
That matters because the future of AI operations will not be won by the organization with the biggest context window.
It will be won by the organization that knows what context is worth paying for.
Sources
Footnotes
-
Google Cloud Blog, “Introducing the Open Knowledge Format,” June 12, 2026: https://cloud.google.com/blog/products/data-analytics/how-the-open-knowledge-format-can-improve-data-sharing/ ↩ ↩2 ↩3
-
GoogleCloudPlatform Knowledge Catalog, OKF
SPEC.md, Version 0.1 Draft: https://github.com/GoogleCloudPlatform/knowledge-catalog/blob/main/okf/SPEC.md ↩ ↩2 ↩3 -
Google AI for Developers, “Gemini Developer API pricing”: https://ai.google.dev/gemini-api/docs/pricing ↩ ↩2
-
Google AI for Developers, “Billing”: https://ai.google.dev/gemini-api/docs/billing ↩
-
Andrej Karpathy, “LLM Wiki” GitHub Gist: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f ↩
-
Google Cloud, “Agent Platform Pricing”: https://cloud.google.com/gemini-enterprise-agent-platform/generative-ai/pricing ↩
-
Anthropic, “Introducing the Model Context Protocol,” November 25, 2024: https://www.anthropic.com/news/model-context-protocol ↩
-
Anthropic, “Donating the Model Context Protocol and establishing the Agentic AI Foundation,” December 9, 2025: https://www.anthropic.com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation ↩
Read next


