Gemma 4 12B: Google's Encoder-Free AI Explained

Writer

When Google dropped Gemma 4 12B, the most upvoted reaction on Hacker News came from an industry insider who essentially said: “I’ve read this three times and I still can’t figure out how it’s possible.” The confusion stems from a single hyphenated word in the documentation: encoder-free. By tearing out the dedicated vision and audio networks—the literal eyes and ears that every multimodal model before it relied on—Google broke what the industry treated as a fundamental law of physics. And yet, the model still sees, still hears, and still runs blazingly fast.
Here is a deep dive into how Google pulled off this architectural shift, why it radically changes local inference, and where the marketing asterisk comes into play.
The Old Paradigm: The Executive and the Translators
To understand the breakthrough, you have to look at the traditional multimodal stack. Historically, a Large Language Model (LLM) is like an executive who only speaks English. If you hand her a photograph or a voice memo, she is blind and deaf to it.
To solve this, we bolted on translators (encoders).
- The Vision Encoder: A massive standalone neural network—often hundreds of millions of parameters—dedicated solely to studying pixels and summarizing them into a token format the LLM can read.
- The Audio Encoder: A similar, distinct network for sound waves.
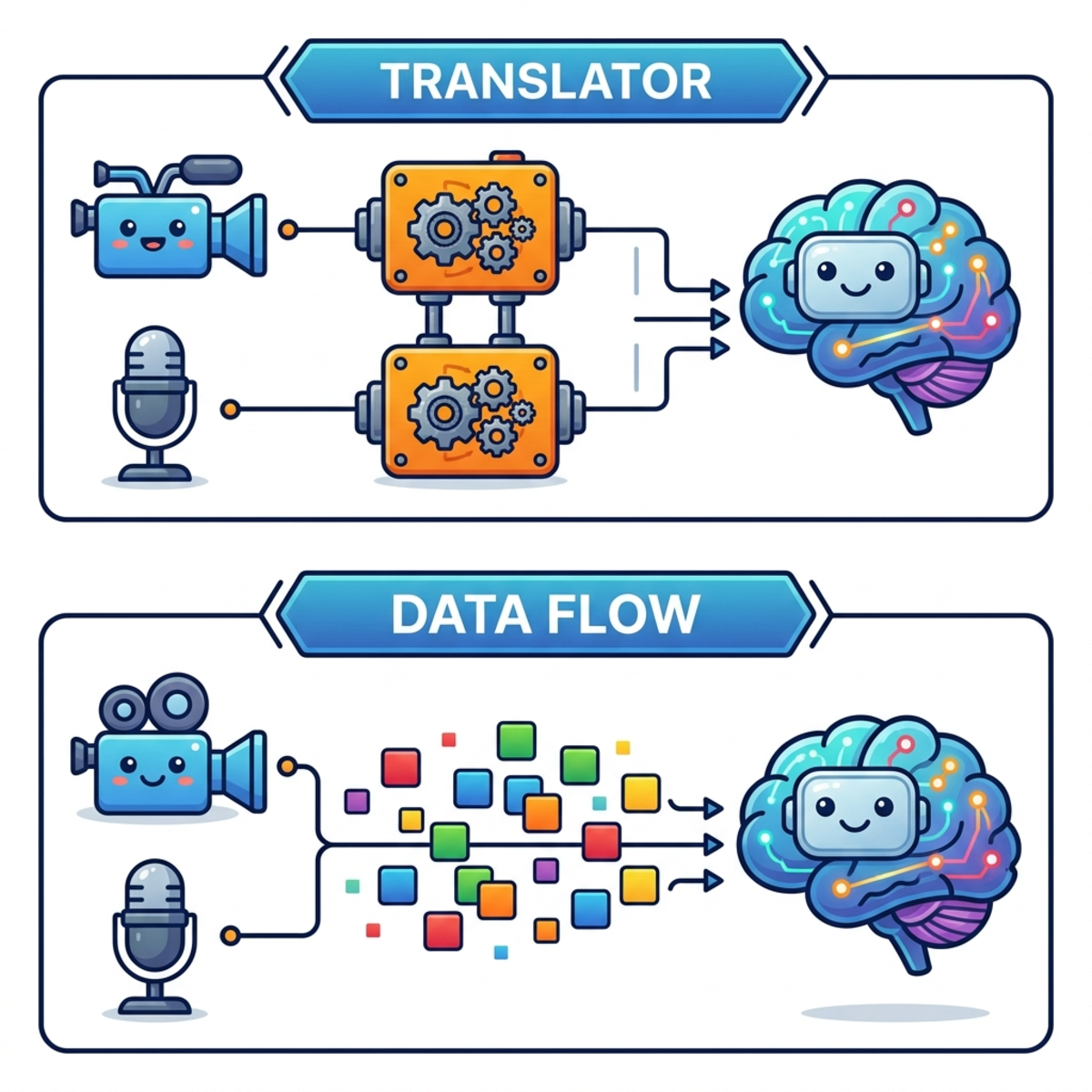
While this works, these translators tax the system. They eat up VRAM because you are loading three discrete networks into memory instead of one. They introduce latency; the LLM cannot output a single token until the translators finish their processing. Furthermore, when you want to fine-tune the model to govern custom agentic engineering workflows via strict agents.md rulesets, you are forced to work around frozen encoder weights—two sealed boxes you aren’t allowed to open.
The Encoder-Free Revolution
Gemma 4 12B fires the translators entirely. Google bet that the core language model is already intelligent enough to process raw multimodal data natively, provided it is reshaped to fit through the exact same slot as text.
How it Sees
Instead of abstracting an image through a massive vision backbone, the model chops the raw image into a grid of tiny tiles (simply lists of raw color values). Through a highly efficient mathematical step—a linear projection—it stamps those values into the correct token shape.
Because a loose pile of tiles lacks spatial context (top-left versus bottom-right matters), the architecture appends simple grid coordinates (positional tags) to each tile. This simple reshape-plus-tag maneuver trades a bulky hundred-million-parameter encoder for a microscopic ~35 million parameters.
How it Hears
Audio processing is even blunter. The raw sound wave is sliced into slivers—just hundredths of a second wide. These slivers bypass any complex acoustic modeling and are pushed through a single reshaping step directly into the input stream.
The Unified Brain
Once the data is reshaped, the model stops caring about modalities. Image tiles, audio slivers, and text tokens all pour into the same unified token pile. A single set of transformer weights chews on everything concurrently. The AI learned to do the translation job inside its own head.
The Engineering Payoffs
This architectural consolidation translates to massive wins for local deployment and infrastructure management.
1. Hardware Efficiency & Memory Footprint

Deleting the encoders evaporates a massive chunk of dead weight. Squeeze this model down with quantization (like a Q6, Q8, or BF16 format), and it fits comfortably into ~8GB of memory. While Google targets mid-range 16GB laptops, if you are running inference on heavy-duty local hardware like an RTX 5090 or a Mac Studio M4 with 128GB of unified RAM, the memory efficiency gives you immense overhead for concurrent multi-turn tasks and robust background agents.
2. Zero-Wait Inference
Because the LLM no longer waits for an external vision encoder to finish its report, time-to-first-token drops dramatically. The data is reshaped, and the model starts reasoning immediately.
3. Frictionless Fine-Tuning
Without frozen encoders blocking the path, you can retrain the entire unified pipeline—sight, sound, and text—in a single, end-to-end pass.
The Reality Check: Benchmarks and Asterisks
Google claims the 12B parameter model punches above its weight, performing near 26B class models and entirely crushing last year’s Gemma 3. However, a technical evaluation requires reading the fine print.
- The Benchmark Illusion: The initial test sheets were graded by Google. On the hardest reasoning benchmarks, the 12B model slips, and the gap between it and true 26B heavyweights opens back up. Parameter count still dictates deep reasoning capability. Vendor benchmarks require independent validation.
- The Qwen Reality: In the broader open-weight ecosystem, model efficiency is fiercely competitive. In fact, a smaller Qwen 9B model actually beat Gemma 12B on five out of eight shared benchmarks during the same release window.
- The Vision Quality Trade-off: Encoder-free does not mean better vision; it means cheaper vision. Dedicated encoders pull richer, more nuanced detail out of complex images. Google acknowledges this internally: they kept the heavy encoders on their larger Gemma 4 flagship models.
- The Context Window Trap: While it “runs on your laptop,” multimodal tokens accumulate incredibly fast. If you feed it a long, dense PDF, the context memory balloons, and a standard 16GB machine will tap out quickly.
The Context Window Trap: 16GB of memory gets rapidly saturated when processing long documents. Watch your context lengths when running locally.
The Strategic Moat: Why Give It Away?
Google didn’t invent the encoder-free concept—labs have experimented with it since Fuyu in 2023, along with others like Eve. What Google did was polish it, scale it, integrate audio, and release the weights for free.
This isn’t charity. Google’s revenue comes from Cloud, Ads, and Devices, not API token access like OpenAI or Anthropic. By dropping a highly capable, free model into the wild, they achieve three things:
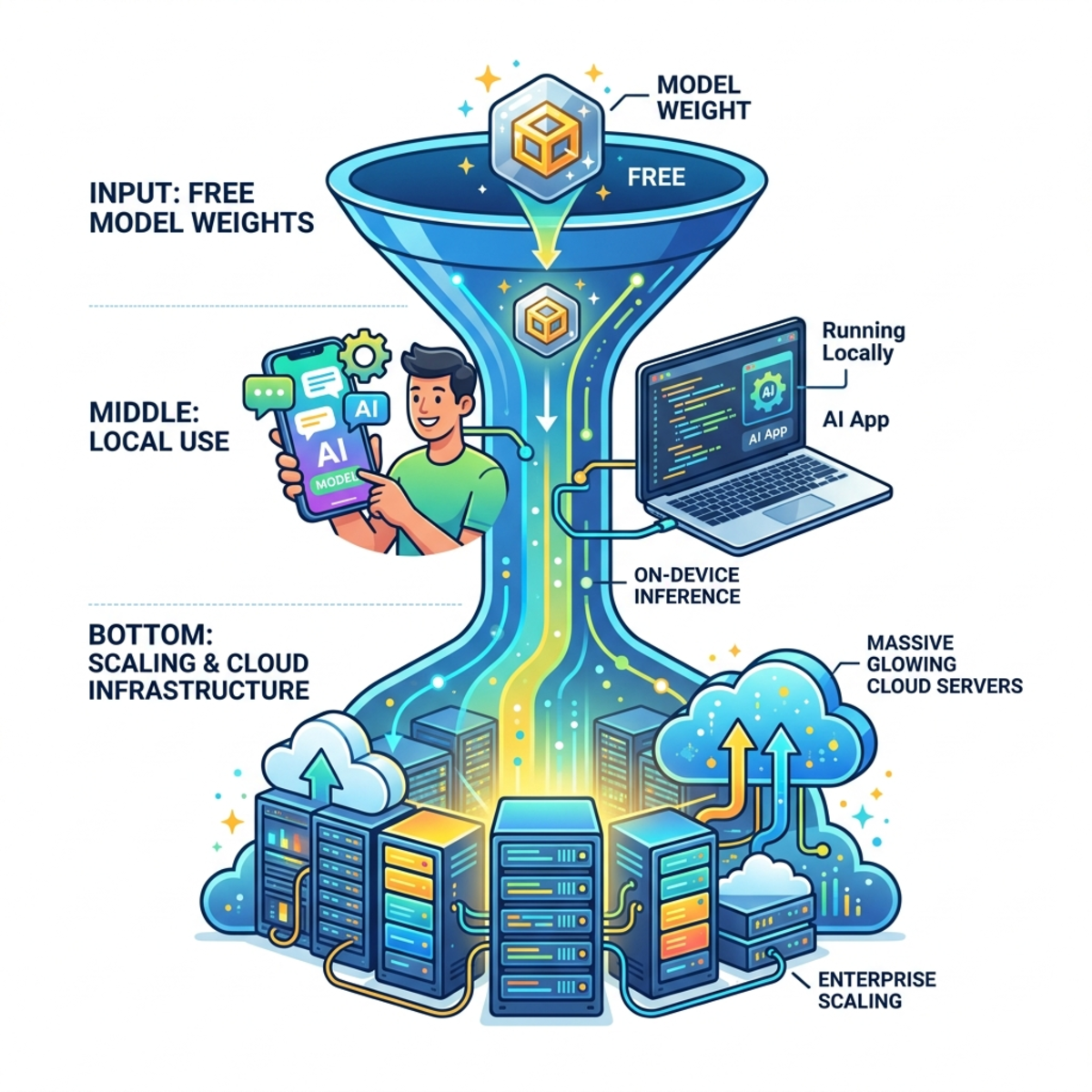
- Commoditize the API: They torch the floor under competitors whose sole business model is selling access to intelligence.
- Achieve Total Reach: A model this light can embed natively inside Android, Chrome, and offline edge devices.
- Build the Cloud Funnel: You pull the model locally, manage your Python environments via uv, and prototype an amazing local tool. But when you need to serve that tool to thousands of users reliably around the clock, consumer hardware fails. Conveniently, Google Cloud is waiting to rent you the servers to scale it. The open model is the hook; the cloud bill is the habit.
Final Verdict
Gemma 4 12B is a masterclass in architectural optimization for the edge. If you need a private, fully offline assistant capable of reading messy documentation, interpreting UI screenshots, or transcribing voice memos securely on local hardware, it is currently in a class of its own.
Just don’t expect it to replace your frontier APIs for deep reasoning, or handle massive concurrent routing. It is a highly specialized, hyper-efficient tool—an AI that finally grew its own eyes and ears instead of renting them.
Read next


