The New SDLC: From Vibe Coding to Agentic Engineering

Writer

The software development life cycle (SDLC) is undergoing a fundamental structural shift. The industry is converging on a standardized set of practices for AI coding, and the surprising part is what stopped mattering: the model itself is no longer the primary differentiator. The competitive advantage now lies in how you engineer the orchestration layer around it.
This article walks through that shift end to end — but it is deliberately practical. Every concept is paired with something you can actually build: a rules file, an MCP config, a hook, an eval. If you read it and don’t have a concrete next step, I’ve failed.
Terms used in this article - Agent — a model wrapped in a loop that can read, plan, call tools, and act, not just emit text. - Harness — everything around the model: rules, tools, hooks, evals, context, and observability. - MCP (Model Context Protocol) — an open standard for connecting agents to tools and data sources (databases, APIs, your file system) through a common interface. - Eval — an automated test that scores an agent’s output against expected behavior, so it can iterate without a human in the loop. - Context window — the working memory the model sees on each call. It is finite and you pay for every token in it.
The Shifting Bottleneck
In a traditional SDLC, gathering requirements takes days, architectural design takes days, and implementation takes weeks. With AI, implementation is compressed into minutes or hours.
Because implementation is no longer the primary constraint, the new bottlenecks are pushed to the edges of the cycle: specification quality upfront and validation at the end.
Concretely, this changes where you spend your time:
| Phase | Old world (manual) | New world (agentic) |
|---|---|---|
| Specification | Loose ticket, clarified in standup | Precise, machine-readable spec the agent executes against |
| Implementation | Days to weeks of typing | Minutes to hours of agent execution |
| Validation | Manual review at the end | Automated evals + gates running continuously |
If you take one thing from this section: the work didn’t disappear, it moved. The hours you used to spend typing now belong to writing sharp specifications and building the checks that catch bad output.
The AI Coding Spectrum
AI coding is not a binary switch between manual typing and full autonomy. It is a spectrum dictated by the maturity of your orchestration:
| Approach | Specification | Verification | Risk Profile | Best For |
|---|---|---|---|---|
| Vibe Coding | Casual, natural-language prompts. | ”Does it seem to work?” | High | Disposable scripts, MVPs, proofs of concept. |
| Structured AI-Assisted | Detailed prompts, structural outlines. | Manual spot-checking and testing. | Medium | Internal tooling, contained feature modules. |
| Agentic Engineering | Engineered specifications (e.g., Markdown schemas). | Automated evals, CI/CD gates, LLM judges. | Low | Production-grade software, enterprise systems. |
Vibe coding is accessible and fast, but it operates at a low granularity of intent. For reliable, scalable automation, you have to move toward agentic engineering.
How to tell where you are right now. Ask one question: when the agent produces something wrong, what catches it?
- If the answer is “me, when I notice” → you’re vibe coding.
- If the answer is “me, when I run the tests” → you’re AI-assisted.
- If the answer is “an automated gate, before I ever look” → you’re doing agentic engineering.
You don’t have to pick one forever. A healthy team vibe-codes a prototype on Monday and runs the validated version through gates on Friday. The skill is knowing which mode the task deserves.
The Harness Is 90% of the System
The most important realization in the current landscape is this equation: Agent = Model + Harness.
The underlying large language model accounts for roughly 10% of the system’s effectiveness. The other 90% is the harness — the layer you completely control. As the industry shorthand puts it: the model is commodity, the harness is moat.
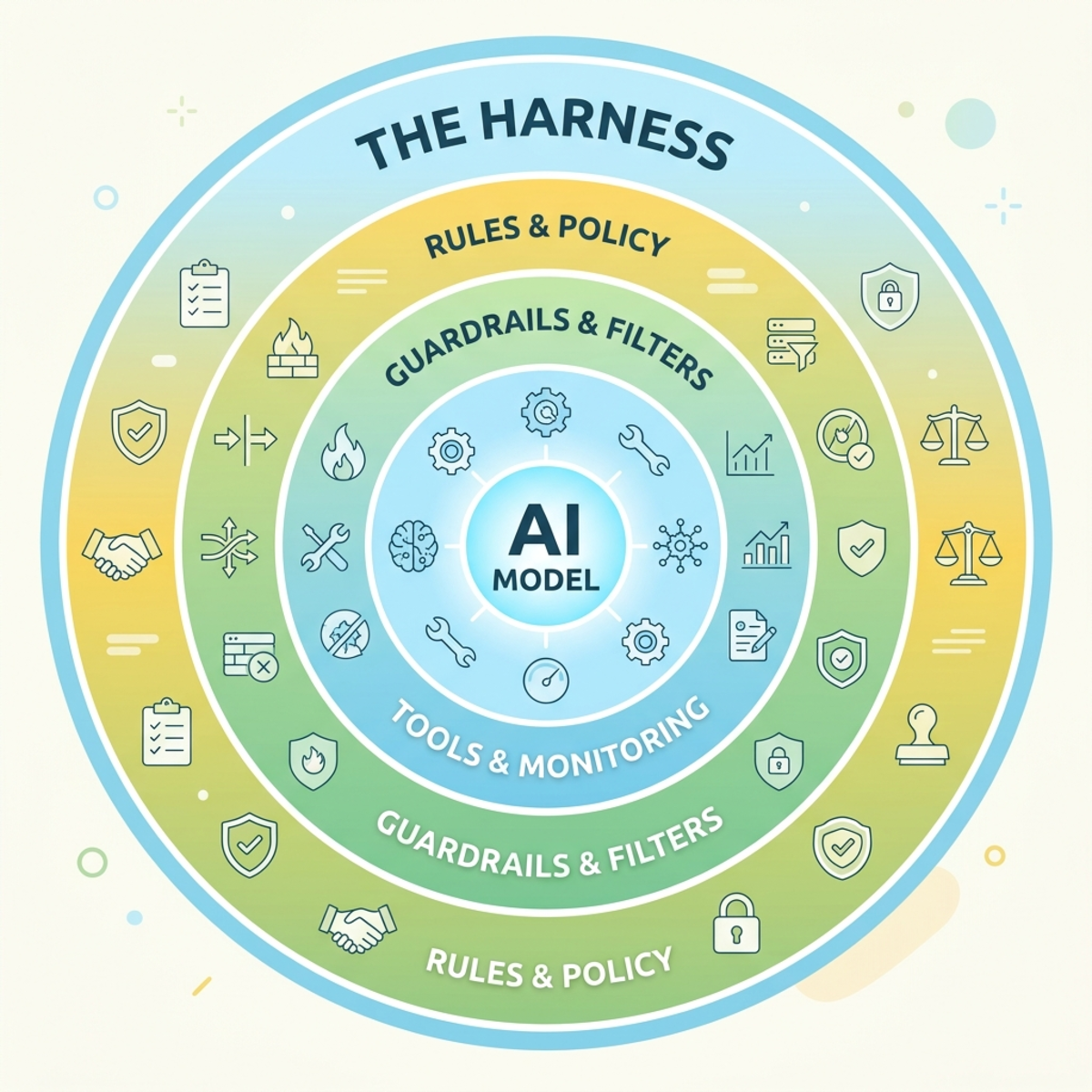
The harness has a handful of components. Below is each one with a concrete artifact, so it stops being abstract.
1. Rules & Guardrails
Static instructions that define boundaries, conventions, and security policy. Most tools load these from a rules file (commonly AGENTS.md, or a tool-specific equivalent) on every session.
This file is the single highest-leverage thing you can write. Every rule here is an error class you never have to catch again.
2. Tools & MCP Servers
Integration points that let the agent read databases, hit your terminal, or call external APIs. MCP standardizes how you wire them up:
With this in place, the agent can inspect your real database schema and open a pull request without you pasting any of it into a prompt. The tools are the difference between an agent that talks about your system and one that operates on it.
3. Hooks & Workflows
Deterministic, repeatable actions that fire automatically at fixed points in the lifecycle. They are not AI — that’s the point. They guarantee a thing happens every time.
Formatting and linting should never be a judgment call the model gets to make. A hook turns “please remember to format” into “it is impossible to commit unformatted code.”
4. Evals & CI Gates
The testing infrastructure that lets the agent iterate autonomously before a human looks. Two flavors:
Deterministic eval — an assertion the answer either passes or fails:
LLM-judge eval — for output that isn’t binary (tone, clarity, completeness), a second model scores it against a rubric:
Evals are what let the agent fix its own mistakes in a loop. Without them, you are the eval — and you don’t scale.
5. Observability
Telemetry to monitor performance, cost, and reliability in production. At minimum, track per task: tokens in/out, dollar cost, tool-call success rate, and eval pass rate over time. (More on what to watch in the Observability section below.)
Maximize the harness. You don’t always need the most expensive frontier model. A well-constructed harness — the right tools, strict guardrails, good evals — often lets a cheaper, faster model outperform an unconstrained premium one. Invest in the 90% you control before you pay up for the 10% you don’t.
The Factory Model and Context Management
Agentic engineering treats development like a factory process. As an engineer, you step back from writing the code to designing the system that produces the code.

A critical best practice is splitting sessions to avoid context rot — the quality decay that sets in when a single session’s context window fills up with stale planning chatter, dead ends, and half-abandoned attempts.
- The Planning Agent ingests specifications and produces a detailed execution plan — written to a durable artifact, e.g.
PLAN.md. - The Coding Agent starts fresh, takes that plan as an immutable input, and executes it in a sandboxed environment.
The plan artifact is the handoff. A good one looks like this:
Because the coding agent starts clean, it never inherits the planner’s confusion — only its conclusions.
Static vs. dynamic context
Managing what enters the context window is the discipline of context engineering. Two kinds of context, two different rules:
- Static context — loaded every session (system prompt,
AGENTS.md, core architecture rules). Highly reliable, but it consumes expensive tokens upfront on every call. Keep it lean — a few hundred lines, not a few thousand. - Dynamic context (progressive disclosure) — loaded on demand. Rather than building brittle multi-agent systems, the industry is moving toward a single lightweight generalist agent that you equip with specialized skills — an RAG lookup, a domain doc, a specific MCP tool — that it pulls in only when the task needs it.
Concretely: don’t paste your entire payments architecture into AGENTS.md. Put one line there — “For payment work, read docs/payments.md” — and let the agent fetch the detail when, and only when, a payment task shows up.
Avoid context bloat. Loading every rule and tool into static context feels safe but makes every call slower, more expensive, and less reliable — models attend worse over padding. Lean into dynamic retrieval. The best context is the smallest context that still answers the question.
Developer Modes: Conductor vs. Orchestrator
This shift changes how you interact with the codebase. You’ll move between two modes:
- The Conductor — micro-managing the AI inside individual files, steering every move. Best for deep debugging, tricky algorithms, or your first exploration of an unfamiliar system. You’re close to the metal because the cost of a wrong turn is high and your judgment is the value.
- The Orchestrator — macro-managing the system. You review pull requests generated by agents running across multiple codebases in parallel. You’re reading diffs and approving outcomes, not typing implementations.
As your harness matures, you naturally graduate from Conductor toward Orchestrator — because the harness now catches the mistakes you used to catch by hand.
A practical rule of thumb: stay a Conductor while you still distrust the output, and only become an Orchestrator for a given workflow once its evals have caught real regressions for you. Trust is earned by the harness, not granted by optimism.
The System Evolution Mindset
When an AI coding assistant produces an error, the standard instinct is to fix the code and move on. Agentic engineering demands a different reflex: run a retrospective with the agent and fix the system instead.
When a failure occurs, ask: where did our context, rules, or integrations fail such that this error was even possible? Then update the harness so that entire class of error is structurally prevented going forward.
A concrete example:
The agent keeps reaching for Python’s stdlib
loggingmodule, but your platform standardizes onstructlog. The vibe-coding response is to fix the import, again, every time it happens. The system-evolution response is one line inAGENTS.md:
- Use structlog, never the stdlib logging module.That single edit retires the error permanently — across every future generation, on every task, for every teammate who shares the file.
This is the compounding loop that makes the approach worth it: the system becomes strictly more reliable with every iteration, because each failure is paid down once instead of forever.
Fix the system, not just the code. Treat every AI error as a bug in your harness. Patching a rule or a tool prevents that class of error permanently, instead of you re-fixing the same mistake on Monday, Wednesday, and Friday.
Token Economics: CapEx vs. OpEx
Adopting these practices fundamentally changes the economics of development. Borrow the capital/operating-expense framing:
- Vibe Coding (Low CapEx, High OpEx): It costs nothing to start, but you burn tokens in a high-operational-expense loop, iterating endlessly on broken “slop code.”
- Agentic Engineering (High CapEx, Low OpEx): Significant upfront engineering hours to build the harness, define MCP servers, and set up evals. But once built, it scales efficiently with a far lower token burn per feature.
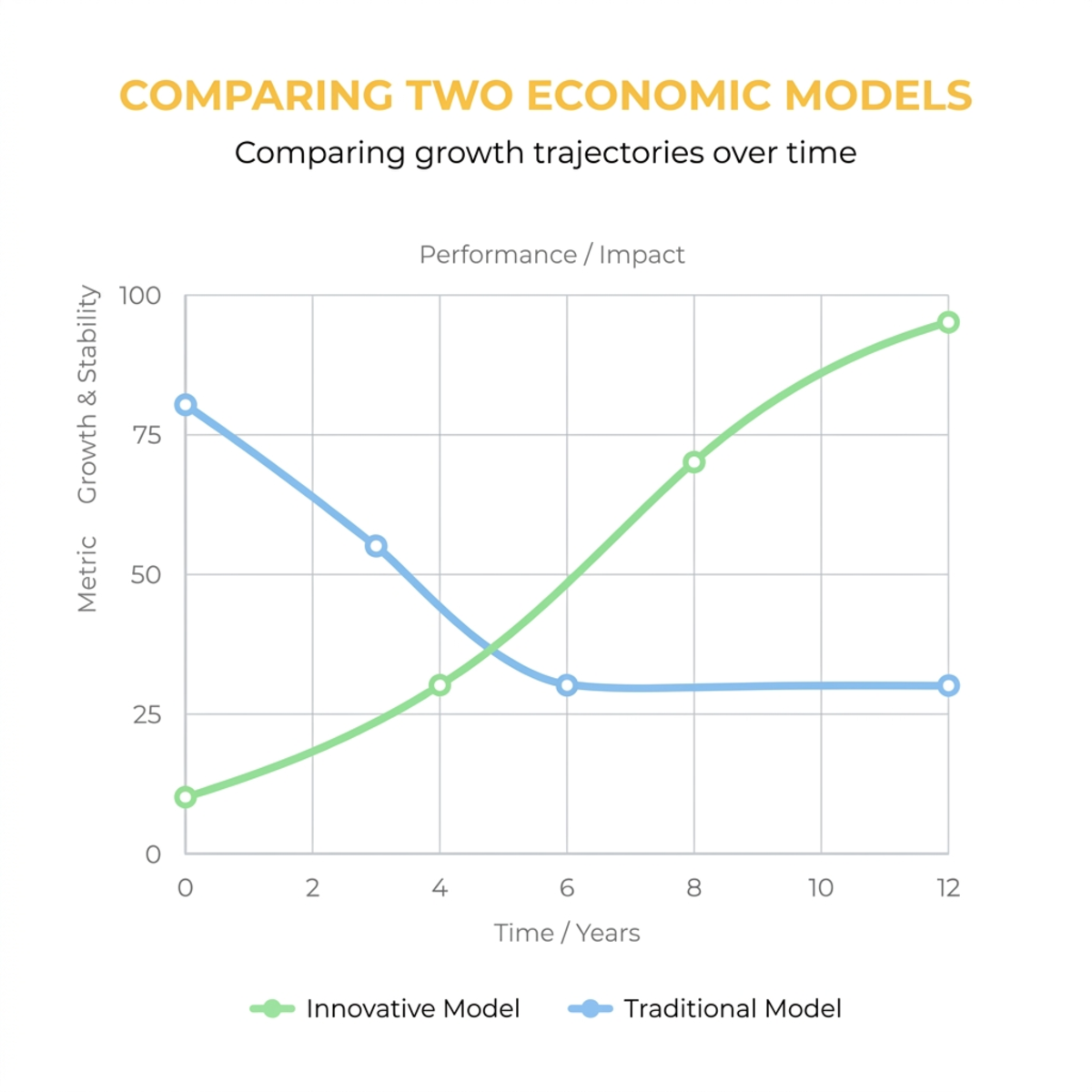
A rough, illustrative comparison for shipping one non-trivial feature (your real numbers will vary — the shape is the point):
| Vibe loop | Agentic loop | |
|---|---|---|
| Upfront cost | ~0 | Harness built once, amortized across all features |
| Iterations to “done” | 20–40 (much rework) | 3–6 (caught early by evals) |
| Tokens per feature | High and unpredictable | Lower and predictable |
| Failure mode | Silent bugs reach production | Bad output fails a gate before review |
The crossover is real: vibe coding wins for the first throwaway script and loses badly by the fiftieth production feature. CapEx you pay once; OpEx you pay every single time.
Production Observability
Agentic engineering extends into production. Managing cost and reliability at runtime calls for AI-native tooling, and semantic caching is one of the highest-leverage layers.
A semantic cache intercepts queries that are meaningfully similar to ones already answered — not just byte-for-byte identical — and serves the stored response before it ever reaches the model, cutting both inference cost and latency. BetterDB is one such tool (semantic and exact-match caching backed by Valkey/Redis); open-source GPTCache and gateway-level caches like Portkey or Helicone solve the same problem from different angles. In practice, similar-query caching reports hit rates in the 20–70% range depending on how repetitive your traffic is — a direct, measurable reduction in spend.
Beyond caching, a minimum production dashboard should track:
- Cost per successful request (keep failed calls and retries separate, or you’ll fool yourself).
- Input/output tokens at p50 and p95 — to catch context creep before it bankrupts you.
- Eval pass rate over time — your single best early-warning signal for quality regressions.
- Tool-call success rate — a flaky MCP server can quietly burn money in retry loops.
If you don’t measure tokens per outcome, you will underestimate your real cost by a multiple. Observability isn’t an afterthought; it’s how you know the harness is still working.
When Not to Reach for Agentic Engineering
Maturity also means knowing when the heavy machinery is overkill. Stay loose when:
- The artifact is disposable — a one-off script, a data spike, a throwaway prototype. Vibe coding is correct here, not lazy.
- You’re still learning the domain — exploration benefits from being a Conductor, close to the code.
- The workflow won’t repeat — harness investment only pays back across repeated runs. Building evals for something you’ll do once is negative ROI.
And avoid these traps on the way up:
- Premature multi-agent architectures. A single well-equipped generalist agent beats a brittle swarm for almost everything. Add agents only when you can name the specific bottleneck they remove.
- Trusting evals you never validated. A green eval that tests the wrong thing is worse than no eval — it manufactures false confidence.
- Skipping the security review on tools. An MCP server with database write access or shell execution is a real attack surface. Scope credentials tightly and prefer read-only access until you have a reason not to.
Your First Week: A Starting Checklist
You don’t build a harness all at once. Build it in the order that pays back fastest:
- Day 1 — Write
AGENTS.md. Stack, conventions, and a short “Never” list. Highest leverage, lowest effort. - Day 2 — Wire one MCP server you actually need (your database or your repo host). Just one.
- Day 3 — Add a post-edit hook that formats, lints, and runs tests automatically.
- Day 4 — Write three evals for your riskiest path. Not a full suite — your three scariest failure modes.
- Day 5 — Turn on cost and eval logging so you can see tokens and pass rate per task.
From there, the engine runs itself: every time the agent fails, hold a retrospective and improve the harness. That loop is agentic engineering.
Key Takeaways
- The bottleneck moved from implementation to specification (upfront) and validation (at the end).
- Agent = Model + Harness, and the harness is ~90% of the result. Invest there first.
- Engineer your context — keep static context lean, disclose dynamic context on demand.
- Split planning from coding to avoid context rot; hand off through a durable plan artifact.
- Fix the system, not the code — every error becomes a permanent harness improvement.
- Pay CapEx once to stop paying runaway OpEx on every feature.
- Measure in production — semantic caching plus a token/cost/eval dashboard keeps it economical.
- Know when to stay loose — vibe coding is the right tool for disposable, exploratory, or one-off work.
Read next


