AI Quality Trends: Autonomous QA, Guardrails & FinOps

Writer

Software quality is no longer just a testing problem. It is becoming a governance, cost, and business-value problem.
That matters because generative AI has changed the unit economics of software delivery. Code can now be produced faster than many organizations can review, test, secure, and govern it. The bottleneck is moving from “Can we build it?” to “Can we prove it is safe, valuable, compliant, and worth the cost of running?”
For IT leaders, FinOps practitioners, tenant administrators, and quality leaders, the winning mental model is simple:
Modern quality engineering is the control plane between software velocity and business risk.
Traditional QA asks: Did the test pass?
Modern quality governance asks:
- Did the release protect revenue-critical journeys?
- Did it reduce operational risk?
- Did it create evidence for audit and compliance?
- Did it avoid runaway AI, cloud, and testing spend?
- Did it give administrators levers to control blast radius?
This article reframes current quality engineering trends through that lens: autonomous QA, AI-driven validation, LLM guardrails, and cost-aware governance.
Executive Takeaways
| Theme | What is changing | Leadership takeaway |
|---|---|---|
| Browser and API testing | Frameworks are reducing brittle workarounds for auth, storage, diagnostics, and traces. | Treat testing platforms as shared infrastructure, not developer utilities. |
| Agentic QA | Tests are shifting from hardcoded scripts to intent-driven workflows. | Preserve business intent separately from implementation details. |
| Vision-based agents | AI can inspect applications like a user, but cost and false positives must be governed. | Route expensive AI testing only where it adds decision value. |
| LLM guardrails | AI apps need evaluation for correctness, safety, groundedness, latency, and cost. | Separate functional quality from liability and model-risk quality. |
| Security remediation | AI can accelerate vulnerability discovery and patch proposals. | Keep humans, independent validation, and audit trails in the loop. |
| FinOps for QA | Testing now consumes compute, tokens, storage, traces, and SaaS licenses. | Measure cost per confident release, not just cost per test run. |
The Mental Model: Quality as a City Traffic System
Think of your software delivery organization as a city.
- Developers are the construction crews.
- CI/CD pipelines are highways.
- Production is the business district.
- QA is no longer a few traffic lights at the end of the road.
- Modern quality engineering is the traffic management system: routing, speed limits, cameras, incident response, and safety zones.
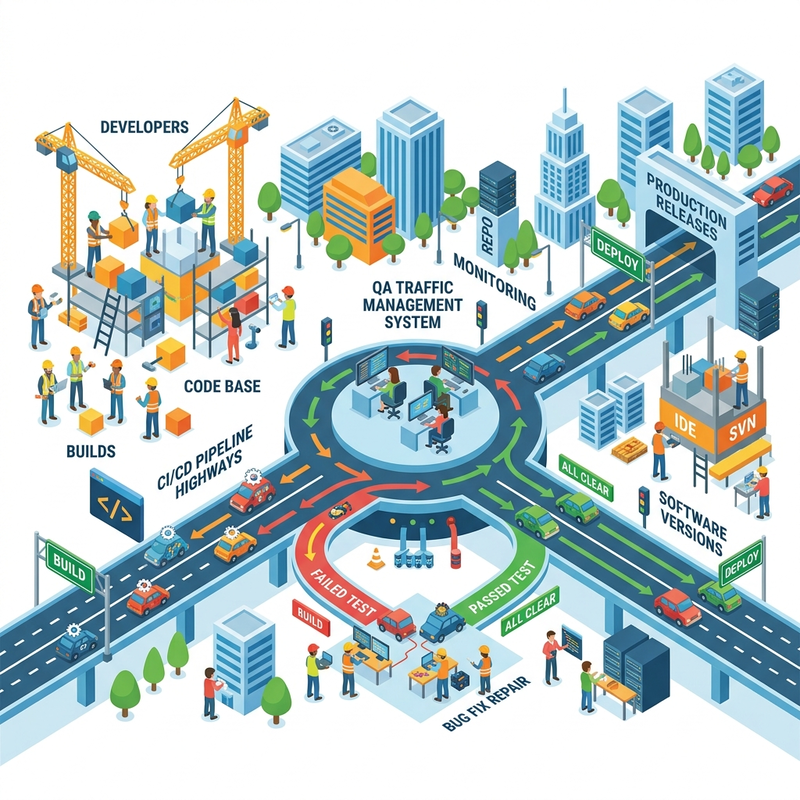
If you add more construction crews with AI coding tools but do not upgrade traffic control, the city does not become more efficient. It becomes chaotic.
That is the core risk of AI-assisted software delivery: creation accelerates before validation catches up.
The governance goal is not to slow teams down. It is to create safe acceleration.
1. Framework Enhancements: Less Fragile Plumbing, More Reliable Evidence
Modern testing frameworks are quietly solving problems that used to create hidden enterprise cost: authentication hacks, state management workarounds, poor diagnostics, and missing traces.
Playwright 1.61: Why Tenant Admins and IT Leaders Should Care
Playwright 1.61 introduced native support for WebAuthn passkeys through a virtual credentials authenticator, first-class local and session storage APIs, improved video retention modes, soft polling assertions, and WebSocket capture in HAR and trace recordings, according to the official Playwright release notes.1
For developers, this sounds like convenience. For IT leaders, it is much bigger.
It means fewer fragile testing exceptions around modern authentication, fewer shared test accounts with risky bypasses, and better evidence when a release breaks.
| Capability | Old world | Newer direction | Business value |
|---|---|---|---|
| Passkey / WebAuthn testing | Skip the flow, use physical test keys, or build brittle mocks. | Use virtual credentials in automated tests. | Better coverage for passwordless and high-assurance login journeys. |
| Browser storage state | Inject or scrape state through custom scripts. | Use direct local/session storage APIs. | Cleaner setup, fewer flaky state bugs. |
| Failure videos | Record everything or miss the one run that matters. | Retain video selectively on failure or retry. | Lower artifact storage waste with better diagnostic value. |
| WebSocket traces | Debug real-time failures separately. | Include WebSocket traffic in HAR and traces. | Better evidence for chat, collaboration, dashboard, and streaming apps. |
Governance Lever: Standardize the Testing Baseline
Tools like Playwright should not be treated as team-by-team preferences in large enterprises. They are part of the engineering control plane.
A practical rollout model:
- Define approved test frameworks for browser, API, mobile, accessibility, and performance coverage.
- Publish secure testing patterns for authentication, test identities, secrets, storage, and data reset.
- Create a shared evidence policy that defines what to retain: traces, screenshots, videos, logs, API payload samples, and retention windows.
- Apply cost controls for artifacts: keep rich evidence for failed or high-risk runs; sample or expire evidence for low-risk green runs.
- Measure flakiness as operational waste, not just engineering irritation.
Directional Cost Intuition: Artifact Storage Is a Silent Tax
This is a directional planning aid, not a quote or product price.
If a suite runs 1,000 browser tests per day and records rich traces or videos for every run, storage and processing can grow quickly. Even if the direct storage cost is small, the operational cost is usually in triage time:
- 100 flaky failures per week
- 10 minutes average triage per failure
- 1,000 minutes per week, or roughly 16+ hours of engineering time
That is two full engineering days spent proving the system did not actually break.
Rule of thumb: record enough evidence to debug failures, not enough to create a forensic archive of every green path forever.
2. API Testing Dashboards: From Logs to Decision Signals
Many organizations still run API tests in CI/CD and then ask engineers to inspect long Newman or pipeline logs. That works at small scale. It fails at enterprise scale.
The strategic pattern is not “another dashboard.” The pattern is turn execution data into release-decision signals.
| Signal | Why it matters | Governance use |
|---|---|---|
| Pass/fail by endpoint | Shows functional breakage. | Block releases for critical APIs. |
| Latency by endpoint | Shows performance drift. | Trigger review before user experience degrades. |
| Failure clustering | Separates isolated failures from systemic failures. | Reduce alert noise. |
| Historical comparison | Detects regressions against prior known-good runs. | Support release readiness decisions. |
| Local or private analysis | Reduces data exposure when test payloads are sensitive. | Align with internal data-handling rules. |
If you build or adopt an API dashboard, focus less on visual polish and more on release policy integration:
- Which failures block production?
- Which failures require owner approval?
- Which failures create backlog items but do not stop the release?
- Which latency thresholds represent customer pain?
- Which evidence is retained for audit?
Directional Cost Intuition: API Testing Cost Is Mostly People Time
For classic API testing, compute cost is often modest. The expensive part is unclear ownership and repeated triage.
A rough planning model:
You do not need perfect math to improve governance. You need enough financial intuition to ask the right question:
Are we paying humans to understand problems that our testing platform should classify automatically?
3. Agentic QA: The Asset Is the Business Intent, Not the Script
The most important mindset shift in autonomous QA is this:
The test script is not the asset. The business workflow is the asset.
A Selenium script that says “click this CSS selector, wait two seconds, assert this string” is implementation detail. The business value is the intent behind it:
- A customer can renew a policy.
- A banker can approve a loan exception.
- A citizen can submit a government service request.
- A sales user can generate an accurate quote.
Agentic testing tools are pushing the industry toward intent-based definitions, self-healing flows, failure analysis, and coverage generation. Some commercial testing platforms are positioning around agentic testing capabilities such as automated coverage generation, runtime recovery, and conversational or agentic failure analysis.2
Legacy vs. Intent-Driven Testing
| Dimension | Legacy script-heavy model | Intent-driven / agentic model |
|---|---|---|
| Primary asset | Test code and selectors | Business workflow and validation intent |
| Maintenance trigger | UI and DOM changes | Meaningful behavior or policy changes |
| Failure mode | Broken selector, timeout, brittle assertion | Ambiguous intent, weak oracle, model drift |
| Governance need | Code review and CI gates | Intent review, risk scoring, evidence, human approval |
| Cost risk | Human maintenance time | AI execution cost, false positives, over-testing |
A Safer Modernization Path
Do not start by replacing the whole test estate with agents. Start by extracting intent.
- Inventory critical journeys: revenue, compliance, security, and executive visibility workflows.
- Classify tests by business value: critical, important, commodity, obsolete.
- Separate intent from mechanics: document what must be true, not just how the old script clicks through the UI.
- Use AI to assist migration, but require human review of recovered intent.
- Pilot agents on high-maintenance, medium-risk journeys before using them on regulated or revenue-critical flows.
- Define escalation rules: when an agent is allowed to retry, self-heal, create a ticket, or block a release.
Governance Lever: Create a Test Intent Registry
A test intent registry is a simple but powerful control.
| Field | Example |
|---|---|
| Business process | Customer onboarding |
| Risk class | Revenue-critical and compliance-relevant |
| Owner | Product operations |
| Test intent | A new customer can complete identity verification and receive confirmation. |
| Evidence required | Screenshot, trace, API response summary, audit event |
| Release gate | Blocker if failure reproduces twice |
| AI agent allowed? | Yes, for exploration; no autonomous production-blocking without human review |
This turns testing from a technical artifact into a business control.
4. Vision-Based QA Agents: Powerful, Useful, and Potentially Expensive
Vision-based QA agents use screenshots, UI state, and language instructions to inspect applications more like humans do. The promise is obvious: fewer brittle selectors and more adaptable validation.
LinkedIn has been publicly reported as using an AI QA Agent approach that combines vision-language models with hybrid execution, including fast deterministic replay for stable paths and slower vision-based planning when the UI changes. Public reporting also described more than 200 valid bugs found and coverage across complex workflows.3
Because much of this space is evolving quickly, treat public case studies as directional signals rather than universal benchmarks.
The Core Architecture Pattern
| Mode | How it behaves | Best use | Cost profile |
|---|---|---|---|
| Deterministic replay | Repeats known stable actions. | Mature, stable workflows. | Low. |
| Vision-based planning | Interprets the screen and decides next actions. | Dynamic UIs, exploratory paths, localization, experiments. | Medium to high. |
| Human review | Reviews uncertain findings. | High-risk or ambiguous failures. | High human cost, but high trust. |
Directional Cost Intuition: Route AI Like Premium Support
Do not send every test through the most expensive agentic path.
A useful analogy: deterministic tests are economy class; vision agents are business class; human SME review is first class.
Use each where it makes sense.
Directional planning aid: if a deterministic browser test costs “1 unit” of compute and platform overhead, a vision-driven agentic run may cost several multiples more because it can involve screenshots, model reasoning, retries, and longer execution time. The exact multiplier depends on tooling, model choice, token/image pricing, and workflow length.
A practical routing strategy:
| Workflow type | Recommended route |
|---|---|
| Stable login smoke test | Deterministic automation |
| Revenue-critical checkout after UI redesign | Deterministic + vision fallback |
| New feature exploratory testing | Vision agent with human-reviewed findings |
| Regulated disclosure or policy answer | Deterministic checks + LLM/RAG evaluation + human sign-off |
| Low-risk visual polish | Sampled vision checks, not every build |
Rule of thumb: use autonomous agents where uncertainty is high and business impact is meaningful. Do not spend AI budget proving the obvious on every commit.
5. LLM Application Testing: Separate Correctness from Liability
LLM applications do not fail like traditional software.
A normal app fails by throwing an error, returning a 500, or rendering the wrong UI. An AI app may fail by sounding confident while being wrong.
That creates a different governance problem.
The Air Canada chatbot case is a useful warning. In February 2024, the British Columbia Civil Resolution Tribunal found Air Canada liable after its chatbot provided misleading bereavement fare information, and the tribunal rejected the argument that the chatbot was separate from the company’s website.4
The lesson is blunt:
If your AI gives the answer, your organization owns the consequence.
The 7-Layer LLM Testing Matrix
| Layer | What it tests | Leadership question | Example control |
|---|---|---|---|
| 1. Functional correctness | Does the app do what it should? | Does it answer the user’s actual task? | Scenario tests and expected outcomes. |
| 2. Safety and integrity | Can it be manipulated or jailbroken? | Can users force unsafe or unauthorized behavior? | Red teaming and prompt injection tests. |
| 3. Edge cases | What happens with weird input? | Does it degrade safely? | Boundary and malformed input suites. |
| 4. Groundedness | Are answers supported by source content? | Can we prove where the answer came from? | RAG faithfulness and citation checks. |
| 5. Regression | Did a prompt, model, or data change make it worse? | Can we compare against last known-good behavior? | Versioned eval datasets and experiment comparison. |
| 6. Latency | Is the experience usable? | Will users abandon the workflow? | Time-to-first-token and end-to-end latency monitoring. |
| 7. Cost | Is usage financially sustainable? | Are we spending appropriately for the value created? | Token, model, and routing budgets. |
Tools and frameworks such as Ragas provide metrics for RAG evaluation, including faithfulness and answer relevance, while LangSmith supports evaluation datasets, regression-testing workflows, and versioned datasets.56
Directional Cost Intuition: LLM Testing Has a Meter Running
Traditional tests mostly consume compute time. LLM tests can consume:
- Input tokens
- Output tokens
- Embeddings
- Vector search calls
- Evaluator model calls
- Reranker calls
- Image or multimodal model calls
- Trace and dataset storage
A simple planning model:
Where evaluator multiplier matters. If every test case is judged by another LLM, you may be paying for both the answer and the grading of the answer.
Rule of thumb: do not run the full LLM evaluation matrix on every commit. Use tiers.
| Stage | Evaluation depth | Purpose |
|---|---|---|
| Pull request | Small smoke eval set | Catch obvious regressions quickly. |
| Nightly | Broader regression set | Detect drift across more examples. |
| Pre-release | Full risk-based validation | Support release decision and audit evidence. |
| Production monitoring | Sampled real-world traces | Detect emerging failure patterns. |
6. Enterprise RAG Validation: From Demo-Driven to Evaluation-Driven
One of the most encouraging enterprise patterns is the move from “demo-driven AI” to evaluation-driven AI.
Lloyds Banking Group described PEGASUS as an in-house package for standardizing how it measures GenAI quality across use cases, including evaluation questions around what to measure, how to measure, and where to measure. The same article describes metrics across prompt, RAG, and summarization scenarios, plus AI-as-judge methodologies with defined criteria.7
Lloyds has also described Athena as an AI-powered knowledge platform using Retrieval-Augmented Generation to provide trusted internal knowledge to more than 35,000 colleagues daily, with governance, explainability, and auditability as key themes.8
The important leadership lesson is not the tool name. It is the operating model:
Production AI needs an evaluation factory, not a demo checklist.
RAG Governance Model
| Control area | What to govern | Why it matters |
|---|---|---|
| Source quality | Approved content, ownership, freshness | Bad knowledge produces bad answers. |
| Retrieval quality | Chunking, ranking, recall, precision | The model cannot answer from documents it never retrieved. |
| Answer quality | Faithfulness, relevance, completeness | Reduces hallucination and unsupported claims. |
| Evaluation set | Versioned representative questions | Prevents cherry-picked demos. |
| Release gates | Minimum scores by workflow class | Turns metrics into decisions. |
| Audit evidence | Prompt, model, sources, answer, score | Supports compliance and incident review. |
Practical Rollout Steps for Tenant Administrators and IT Leaders
- Define AI application classes: internal assistant, customer-facing assistant, regulated workflow, productivity copilot, support chatbot.
- Set risk-based evaluation requirements per class.
- Require source ownership for any RAG corpus.
- Version evaluation datasets and tag production baselines.
- Create escalation paths when groundedness or safety scores drop.
- Track cost per successful answer, not just total AI spend.
- Review model or prompt changes like configuration changes, not casual content edits.
7. Autonomous Security Remediation: Move Fast, But Do Not Let the Model Judge Itself
AI-assisted security is moving from vulnerability discovery toward patch generation and remediation support.
OpenAI’s June 2026 Daybreak announcement describes updated Codex Security capabilities, GPT-5.5-Cyber limited to trusted defenders, a Daybreak Cyber Partner Program, and Patch the Planet with Trail of Bits, HackerOne, Calif, researchers, and open-source maintainers. OpenAI also stated that the bottleneck is shifting from finding vulnerabilities to patching them.9
That is strategically important. If AI increases vulnerability discovery faster than organizations can validate and patch, the backlog can get worse before it gets better.
The Security Governance Trap: The Self-Judging Antipattern
Avoid this pattern:
One AI model writes the code, proposes the security fix, validates the security posture, and declares the patch safe.

That is not governance. That is circular confidence.
A safer model:
| Step | Control |
|---|---|
| AI identifies candidate issue | Treat as untrusted finding until validated. |
| AI proposes patch | Require code owner or security owner review. |
| Independent tests run | Use static analysis, unit tests, integration tests, fuzzing, or separate evaluators. |
| Human approval for high-risk areas | Especially auth, crypto, payments, identity, and data access. |
| Evidence retained | Store finding, patch, test result, reviewer, and decision. |
Directional Cost Intuition: Patch Volume Can Create Review Debt
AI can create more findings and patches than humans can review. That sounds productive until the security team becomes the bottleneck.
A useful metric:
If review debt grows every week, automation is generating inventory, not reducing risk.
Rule of thumb: measure validated risk reduction, not generated findings.
8. Certification and Skills: Upskill for Governance, Not Just Tools
Automation skills still matter. Robot Framework Certified Professional (RFCP) is positioned by the Robot Framework Certification Program as an official certification backed by the Robot Framework Foundation. Testsmith also offers accredited RFCP training, including a self-paced online course.10
But the leadership message is broader: the next generation of quality professionals needs more than scripting skills.
They need to understand:
- Business-process risk
- Evidence and audit requirements
- AI evaluation metrics
- FinOps and cost routing
- Security validation
- Data governance
- Human-in-the-loop operating models
The best QA engineers are becoming quality architects.
The Practical Governance Playbook
If you are responsible for quality, cost, tenant administration, or AI governance, start with these levers.
1. Classify Your Quality Workloads
| Workload | Risk | Recommended control |
|---|---|---|
| Commodity UI regression | Low to medium | Deterministic automation, sampled evidence. |
| Identity and access flows | High | Strong auth testing, trace evidence, admin review. |
| Customer-facing AI chatbot | High | RAG evals, safety tests, groundedness checks, legal-approved content. |
| Internal productivity assistant | Medium | Usage monitoring, feedback loop, dataset regression. |
| Security remediation | High | Independent validation and human approval. |
2. Route Tests by Value and Cost
| Test type | Run frequency | Why |
|---|---|---|
| Fast deterministic smoke tests | Every PR | Cheap, fast signal. |
| Critical journey tests | Every merge or release candidate | Protect business outcomes. |
| Vision-agent exploratory tests | Scheduled or pre-release | Useful but costlier. |
| Full LLM evaluation suite | Nightly or pre-release | Too expensive for every commit. |
| Human SME review | Exceptions and high-risk changes | Preserve trust where automation is insufficient. |
3. Define Administrative Limits
Tenant administrators and platform owners should define limits before usage scales:
- Maximum agent runs per environment per day
- Maximum LLM evaluation spend per project per month
- Approved models and evaluation tools
- Retention policy for traces, recordings, prompts, and responses
- Data-loss prevention rules for test payloads
- Approval workflow for customer-facing AI behavior changes
- Incident playbook for hallucinations or unsafe outputs
4. Measure the Right KPIs
Move beyond test count and pass rate.
| KPI | Why it matters |
|---|---|
| Cost per confident release | Links spend to release assurance. |
| Flaky failure triage hours | Quantifies operational waste. |
| Critical journey coverage | Protects revenue and trust. |
| LLM groundedness trend | Shows whether AI answers remain source-backed. |
| Regression escape rate | Measures missed quality issues. |
| Review debt for AI-generated findings | Prevents security backlog inflation. |
| Evidence completeness | Supports audit and incident response. |
Final Opinion: Autonomous QA Is Not a Replacement for Governance
Autonomous QA will reduce manual effort. Vision agents will find bugs scripts miss. LLM evaluators will catch answer-quality problems that unit tests cannot see. AI security tools will accelerate remediation.
But none of that removes the need for leadership control.
The organizations that win will not be the ones that simply add more AI to testing. They will be the ones that build a quality control plane:
- Intent is documented.
- Risk determines test depth.
- Cost is routed intelligently.
- Evidence is retained deliberately.
- AI findings are independently validated.
- Administrators have clear limits and escalation paths.
The punchline is simple:
In the AI delivery era, quality engineering is not the department that says “no.” It is the system that lets the business say “yes” safely, repeatedly, and at a cost it understands.
References
Footnotes
-
Playwright release notes, Version 1.61: https://playwright.dev/docs/release-notes ↩
-
mabl agentic testing and failure-analysis materials: https://www.mabl.com/ and https://university.mabl.com/agentic-failure-analysis ↩
-
Public reporting on LinkedIn QA Agent: https://www.startuphub.ai/ai-news/tech/2026/linkedin-s-ai-tester-sees-bugs ↩
-
American Bar Association summary of Moffatt v. Air Canada: https://www.americanbar.org/groups/business_law/resources/business-law-today/2024-february/bc-tribunal-confirms-companies-remain-liable-information-provided-ai-chatbot/ and CBC coverage: https://www.cbc.ca/news/canada/british-columbia/air-canada-chatbot-lawsuit-1.7116416 ↩
-
Ragas faithfulness and answer relevance documentation: https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/faithfulness/ and https://docs.ragas.io/en/v0.1.21/concepts/metrics/answer_relevance.html ↩
-
LangSmith regression testing and dataset management documentation: https://www.langchain.com/blog/regression-testing and https://docs.langchain.com/langsmith/manage-datasets ↩
-
Lloyds Banking Group, “PEGASUS: evaluation driven development for GenAI”: https://www.lloydsbankinggroup.com/insights/pegasus-evaluation-driven-development-for-genai.html ↩
-
Lloyds Banking Group Medium article, “Athena: Building an AI-Powered Knowledge Platform at Lloyds Banking Group”: https://medium.com/ai-at-lloyds-banking-group/athena-building-an-ai-powered-knowledge-platform-at-lloyds-banking-group-6b18107e23c9 ↩
-
OpenAI, “Daybreak: Tools for securing every organization in the world”: https://openai.com/index/daybreak-securing-the-world/ ↩
-
Robot Framework Certification Program and Testsmith RFCP training: https://cert.robotframework.org/ and https://onlinecourses.testsmith.io/robot-framework-certified-professional-accredited ↩
Read next


